平安时代汉字字书研究综合数据库
▾ 名称:平安時代漢字字書総合データベース
▾ 英文:Hanzi Dictionaries in Early Japan,简称HDIC
▾ 中文:平安时代汉字字书研究综合数据库
▾ 链接:点击这里
简介
平安时代汉字字书综合数据库项目,由日本北海道大学文学研究院开发运营。该项目对汉字字书的字头及注释进行数字化,构建可自如检索的系统,并将所有数据公开,以助力推进学术研究的发展。平安时代(日语:平安時代/へいあんじだい heianjidai,794年-1185年)是日本古代的最后一个历史时代。
该项目最初在1994年由日语研究专家池田証壽发起。近年来,由于汉字编码技术和日本数字人文领域的发展,数据库规模日益庞大。自1991年以来,该项目以Unicode编码为基础;至2017年,该项目基于Unicode 10.0版本发布了《篆隷万象名義》的全文数据。目前,项目团队仍在积极建设发展字书数据库,此项目也被日本数字人文协会提名给今年即将举办的DH2022大会。
资源
该项目主要包含三种字典:《篆隷万象名義》、《新撰字鏡》、《類聚名義抄》。《篆隷万象名義》的全文资料最早于2016年由该项目组发布,也是向公众开放的第一部早期日本字典数字资料。《篆隸萬象名義》是《玉篇》的删节版,因为《玉篇》原本已经佚失,而《篆隷万象名義》与《玉篇》原本的内容极相近,因此是研究《玉篇》原本的珍贵资料。《新撰字鏡》与《類聚名義抄》也是古代日本的重要字书,是研究汉、日语史极为有用的资料。
目前该数据库一共含有4部日本平安时代的汉字字书,和3部编撰于中国的字书(括号内为该项目中对应的简称):
- 高山寺本《篆隷万象名義》(KTB)
- 天治本《新撰字鏡》(TSJ)
- 図書寮本《類聚名義抄》(ZRM)
- 観智院本《類聚名義抄》(KRM)
- 原本《玉篇》殘巻(YYP)
- 宋本《大広益会玉篇》(SYP)
- 高麗本《龍龕手鏡》(GLS)
其中宋本《玉篇》底本为印刷版,其他均为手稿。截至2022年5月,除了两部《類聚名義抄》和《龍龕手鏡》外,其他基本字书的图像和全文(full text)都已经开放获取。此外,该项目也将《说文》、宋本《广韵》、《康熙字典》、《切韵》残卷作为外部参考。
使用
该项目的目标是将库内所含的字书制作成可搜索的数据库,并提供图像和全文数据。其数据库的查看界面被称为“HDIC Viewer ”,用户可使用浏览器在线对它进行查看。
HDIC Viewer
HDIC Viewer最初是作为HDIC数据库的用户界面进行开发的,目的是提供发布和搜索功能。随着HDIC文本修订次数的增加和新技术的应用,HDIC Viewer被扩展为一个更大的、包括HDIC以外其他古籍词典的数据库。
下面我们以“宋本『大広益会玉篇』全文データベース”为例,介绍其使用方法。
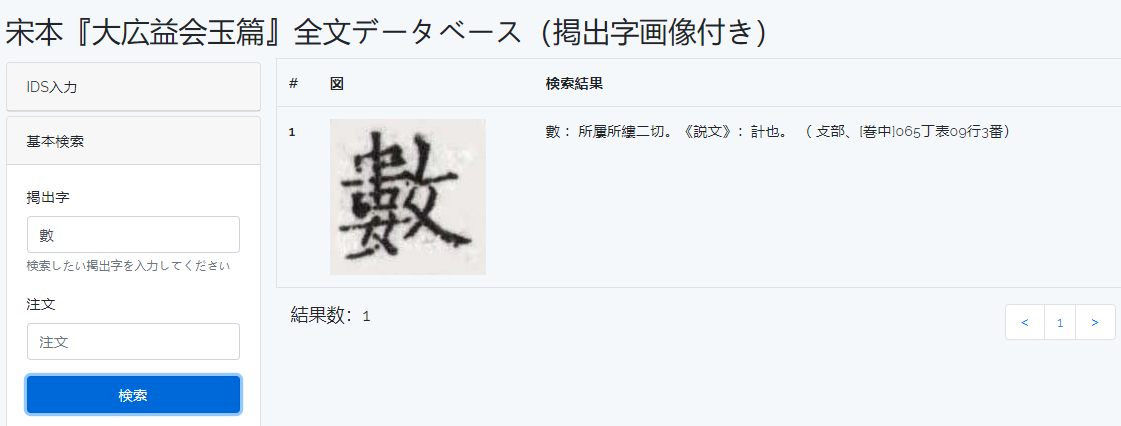
如图,在宋本《玉篇》搜索“數”字,返回了字头图像、反切、释义以及其出现位置。
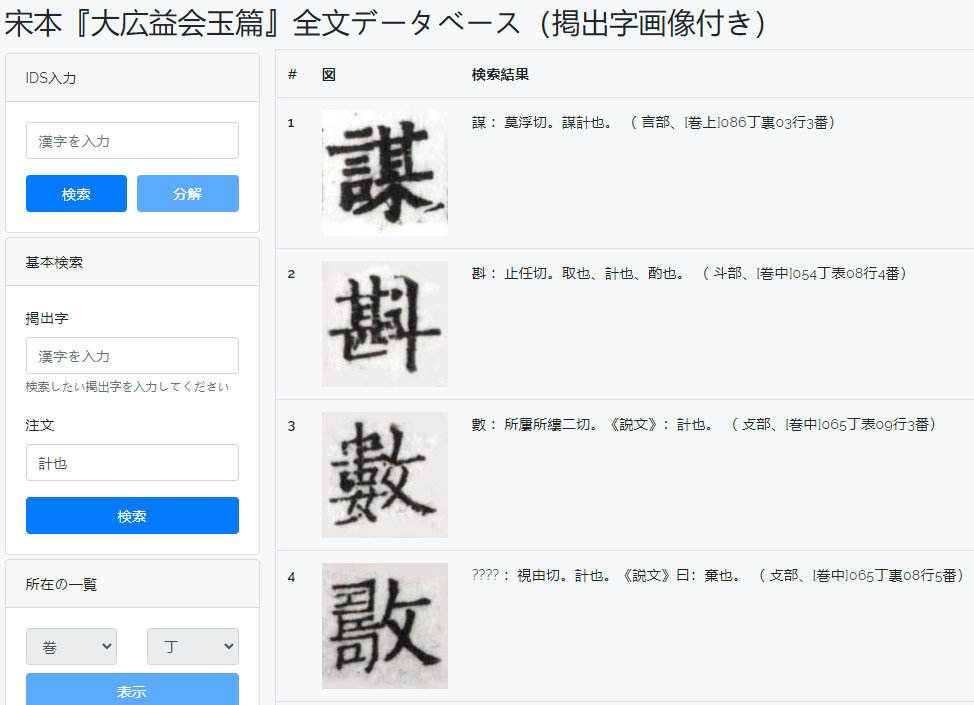
除了按字头(揭出字)搜索外,也可以按释义(注文)进行检索。如图,我们在注文中搜索“計也”,能返回所有含有该注释的汉字。
目前,HDIC Viewer中公开的数据有《万象名義》、《新撰字鏡》、観智院本《類聚名義抄》和宋本《玉篇》。其扩展篇目还包括《大字典》《倭玉篇》《本草和名》《一切经音义》,但现阶段只对内部公开。
全文数据
该项目将全文数据发布在GitHub平台。自2015年发布数据以来,一直在不断更新,上次更新时间为2022年3月20日。链接为: full text (Github)
正如上文提及,所有的汉字都使用Unicode编码。一些尚未收录于Unicode中的字,则使用表意文字描述序列(ideographic description sequence,简称IDS)进行描述。IDS是一种使用表意文字描述字符(IDC,即⿰⿱⿲⿳⿴⿵⿶⿷⿸⿹⿺⿻,Unicode码由U+2FF0到U+2FFB)和部分字符来描述整个字符的方法。这些字符用以描述字的结构,如“謝”字为左右结构,则可描述为“⿰言射”,这一方法常用于汉字编码中。
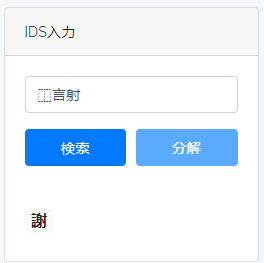
如图,在HDIC Viewer中也可以采用IDS进行检索。
该项目的全文数据采用了TSV数据格式进行保存。TSV与CSV格式类似,是一种简单文本格式,用于以表格结构存储数据。表中的每条记录是文本文件的一行,记录的每个字段值都由制表符进行分隔。因此,TSV是十分普遍的数据存储格式。

上图为宋本《玉篇》TSV文件的部分示例(在Notepad++软件中打开)。
评价
虽然该项目的网站设计较为简单,但内容相当丰富。其文本数据保存在GitHub平台,较为稳定,且所有数据开源,采用CC BY-SA 4.0协议,研究者可自由地使用其数据。TSV格式的互操作性强,在词典学和信息处理方面都得到广泛支持,可在不同计算机程序之间进行数据交换。
同时,该项目也展示了较好的跨文化性。其项目团队本身就具备国际化特点,由中日研究人员共同参与开发,项目网站的“关于”页也提供了多语言介绍。该项目的研究内容基于汉字,包含了整个汉字圈范围内的文献资料,对于跨文化的学术研究能起到一定推动作用,是一个极佳的项目案例。
引用
更多关于此项目的介绍,可参见:
Ikeda, Shoju, and LI Yuan. “Building a General Database System of Chinese Character Dictionaries in Early Japan : Tenreibanshōmeigi in the HDIC Project.” Journal of the Graduate School of Letters 13 (March 2018): 49–64.
LIU, Guanwei, LI Yuan, and Ikeda Shoju. “Expansion of Integrated Database of Hanzi Dictionaries in Early Japan and Its Combination with Japanese Readings.” 情報処理学会研究報告(Web) 2015, CH-106 (2015): 106.