Digital Tale of Genji 数字源氏物语
▾ 数据库名称:Digital Tale of Genji (数字源氏物语)
▾ 网站链接:点击这里
简介
“数字源氏物语”项目汇集了众多《源氏物语》的资料,包括草书本和校异本图片、原文及译文文本等。这些资料来源于日本各大图书馆和研究机构,如国立国会图书馆、东京大学综合图书馆、九州大学文学院等等。读者可以在这个网站内一站式阅读并且比较各版本的《源氏物语》文本和插图影像。
该项目由来自东京大学、人文情报学研究所等机构的研究人员共同协力完成。项目最早源于2019年6月,东京大学将图书馆所藏《源氏物语》资料公之于众,在此基础上,研究人员进一步开发了这个《源氏物语》综合研究平台。
对读系统
该项目最为突出的特点是提供了不同版本之间对照阅读的可能性。《源氏物语》版本复杂,读者可以同时选取多种版本进行比对。对于书中的插图以及衍生的“百人一首”,该项目也单独提供了对照阅读的浏览方式。
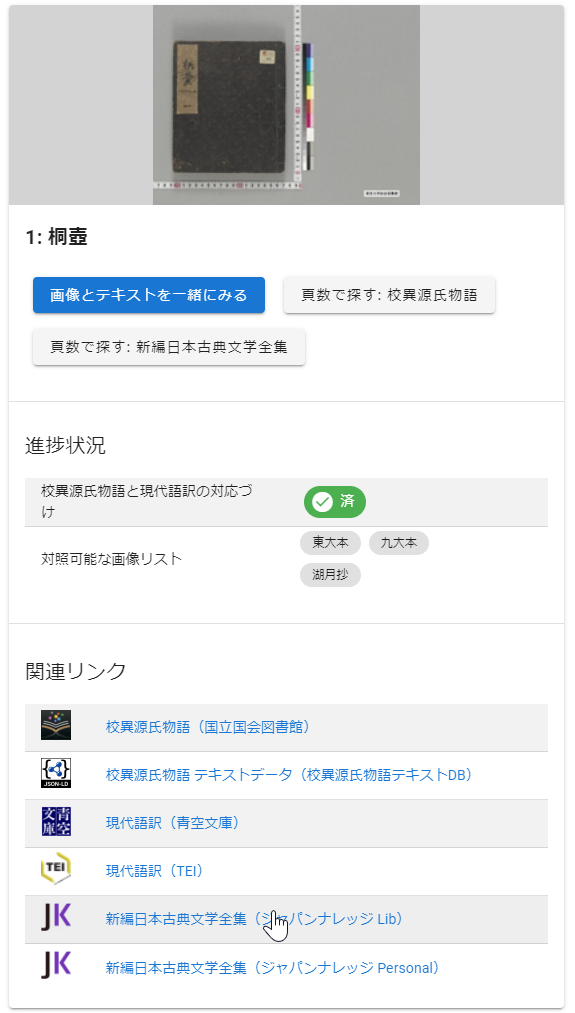
如图,该网站为每一卷目都配备了详细的链接和信息,可根据卷名查看其文本、图像、、以及各版本的不同来源。
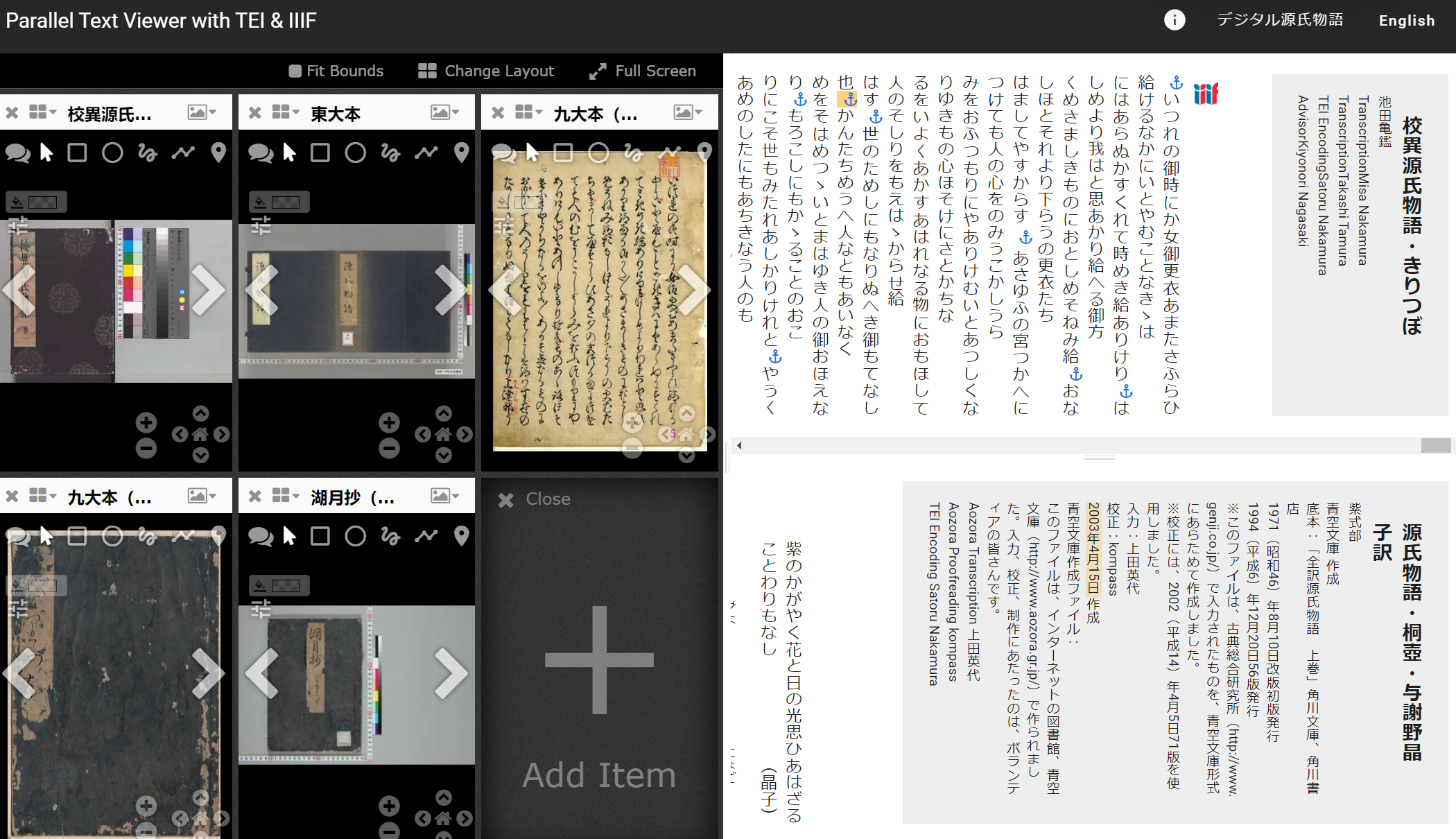
如图,我们选取第一卷《桐壶》,可同时查看其文本和图像数据。
多版本对读
网站提供了五个版本的《源氏物语》全文图片。如下图所示,在“比较”功能中,读者可以在窗口内同时查看多个不同版本。从左往右起分别为:湖月抄、东大本、九大本(古活字版)、九大本(無跋無刊记整版本)、校异源氏物语。
插图比较
《源氏物语》插图大多以《绘入源氏物语》版本为基础,如今日本教科书中也仍在使用其中的插图。所有插图共可分三种类型:大本、横本和小本。一共有226幅插图,若将其中12幅展开图分两页计算,则插图总数为238幅(该项目采用此方法对图片编号)。
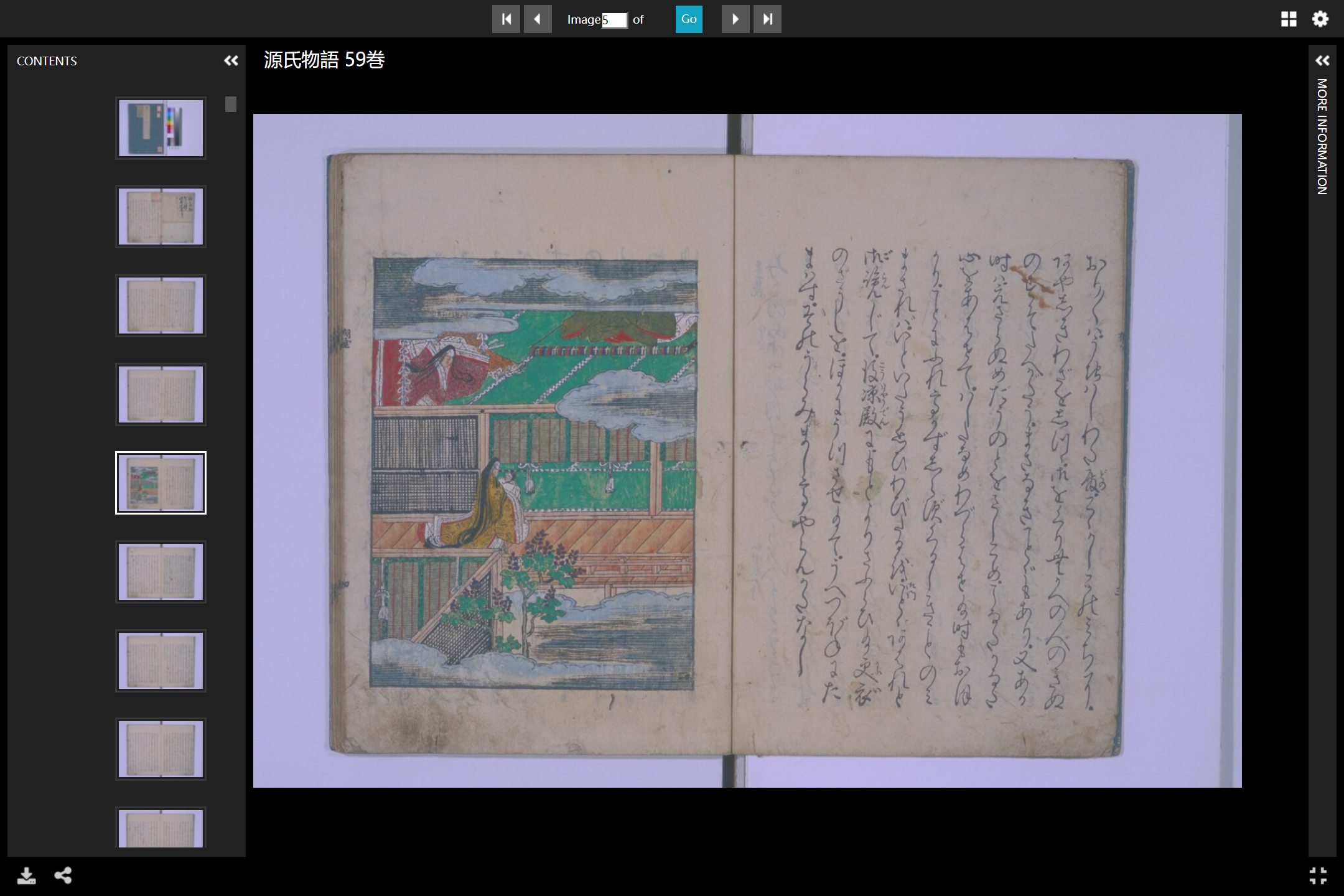
图为京都大学藏本插图示例。
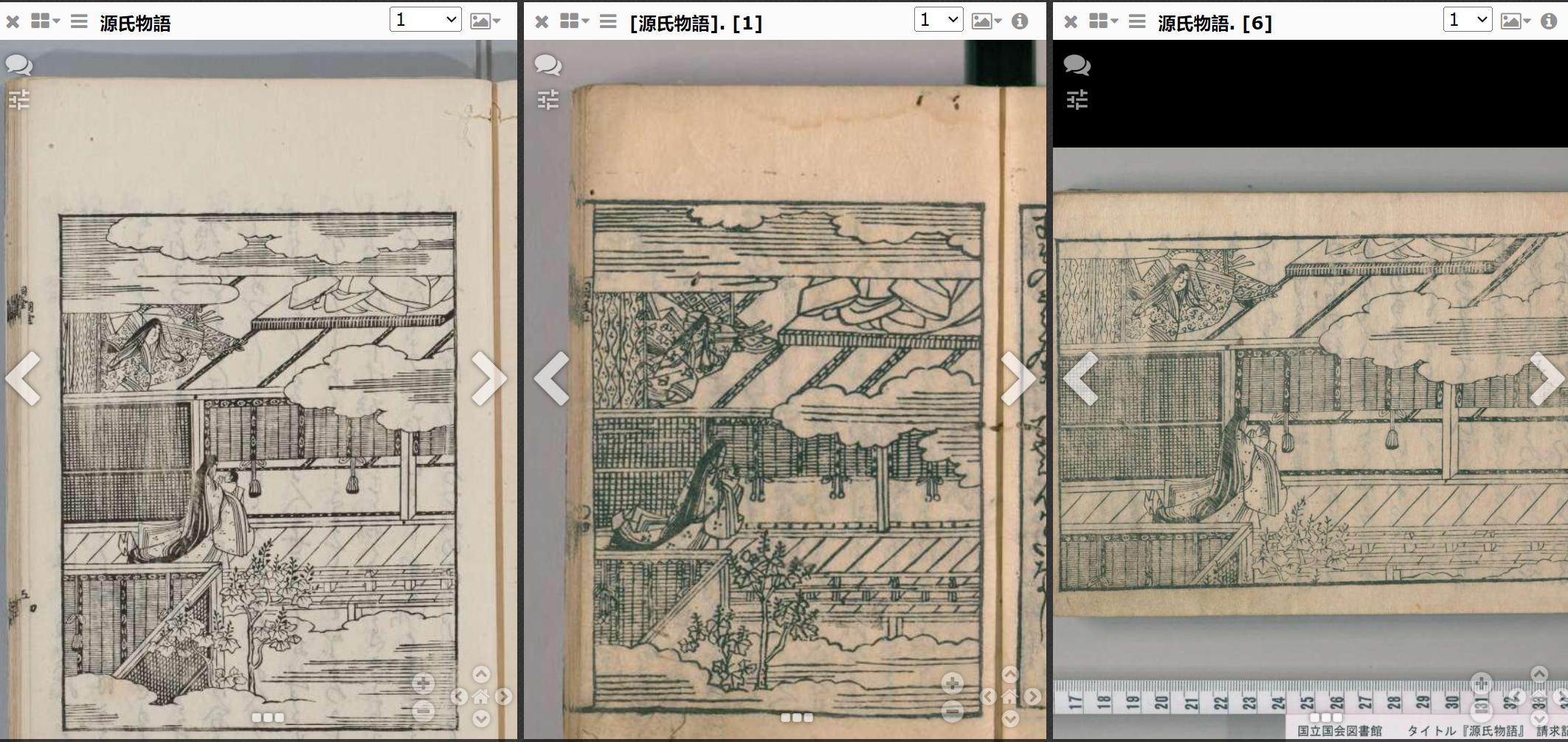
如图,在该网站中,读者可以自行对三个插图版本进行对比查看。
《源氏百人一首》面部比较
《源氏百人一首》是日本“百人一首”歌集的一种,它将《源氏物语》中的人物所创作的诗歌逐一收集起来,并以歌牌的方式进行介绍。但在不同的版本中,对人脸的描绘有所不同。在“パタパタ顔比較”页面,读者有机会对来自不同版本的人物面部进行比对。网站提供了“大阪府立大学”收藏的“引目”版,以及“奈良女子大学”的“开目”版。二者在眼部的描绘上大相径庭。
该功能所用的图像比较工具为“vdiff.js”,由日本人文学开放数据中心(ROIS-DS 人文学オープンデータ共同利用センター)研发,能使用户快捷地“比较阅读”,该工具可以将多张图片叠加查看。
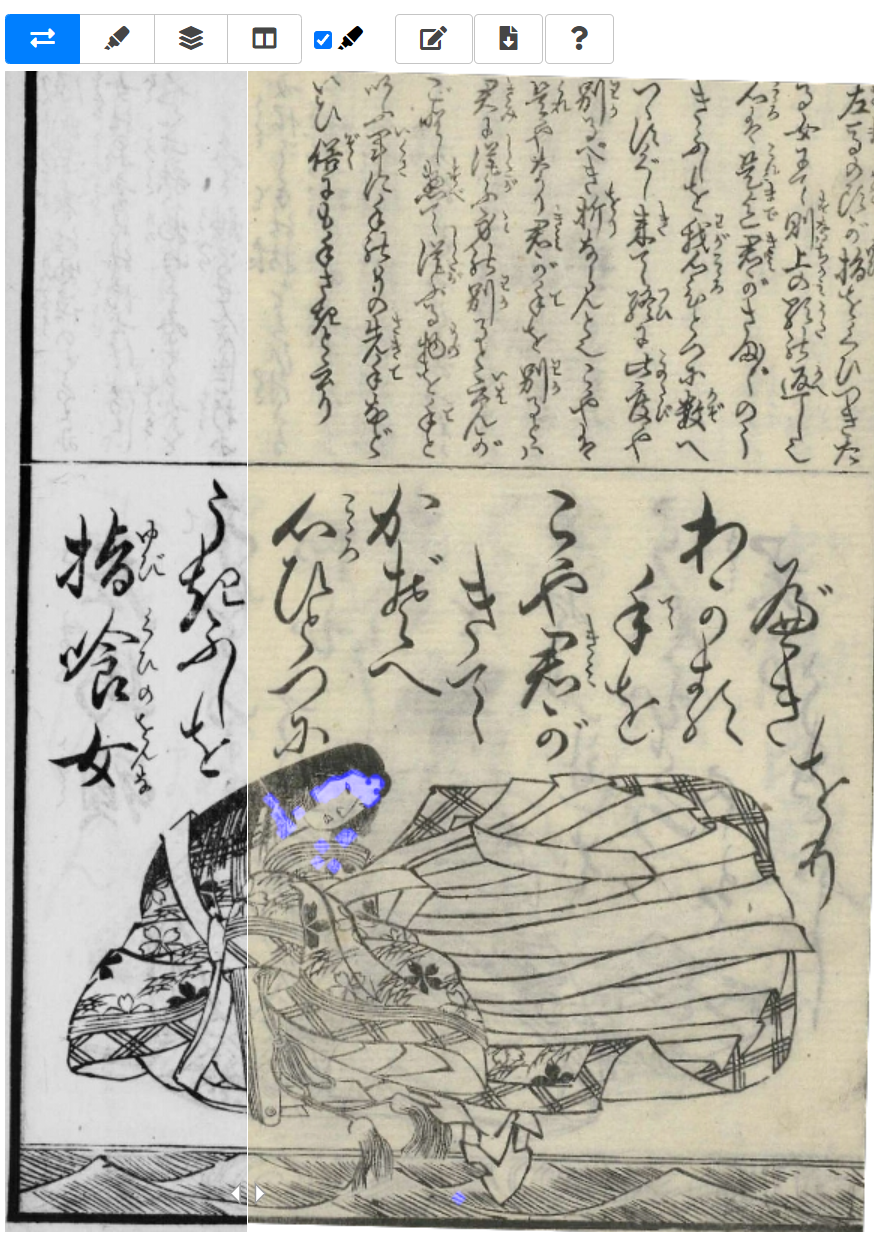

如图,移动准线,可以快速对比两张图片的差异。这种比较手稿的阅读方式,被该网站称为“啪嗒啪嗒(パタパタ)”。
OCR文本
虽然很多机构已经出版了《源氏物语》全文图像版,但即便读者能熟练掌握变体假名和草书体(即“くずし字”),要在2000多张图片中进行关键词定位还是太过耗费精力。因此,日本人文学开放数据中心为《源氏物语》全文图像进行了OCR识别(OCR即“光学字符识别”,能将图片数据录入为机器可识别的编码)。以《校异源氏物語》和《新编日本古典文学全集》的页码标准,设定了不同版本之间交叉引用的方式(这一工作主要由人工完成)。而草书字的OCR则为自动化处理,由日本人文学开放数据中心的专业OCR团队完成。
文本库
该项目为《校异源氏物语》制作了文本库,放置于一个GitHub主页上。

图为其界面,依然是以卷目为单位。很明显,网站为读者提供了三种格式的数据:IIIF画像(国际图象互操作框架)、符合TEI(文本编码标准)的XML文档(一种标记性的数据表示格式)、以及JSON-LD(结构化数据片段)文档。
文本检索
网站提供了基于OCR文本库的搜索功能,在“AI画像検索版”页面,可键入搜索关键词进行搜索。检索结果的“相似度”值,代表《校异》本的OCR与各个草书体版本自动OCR结果的相似度。
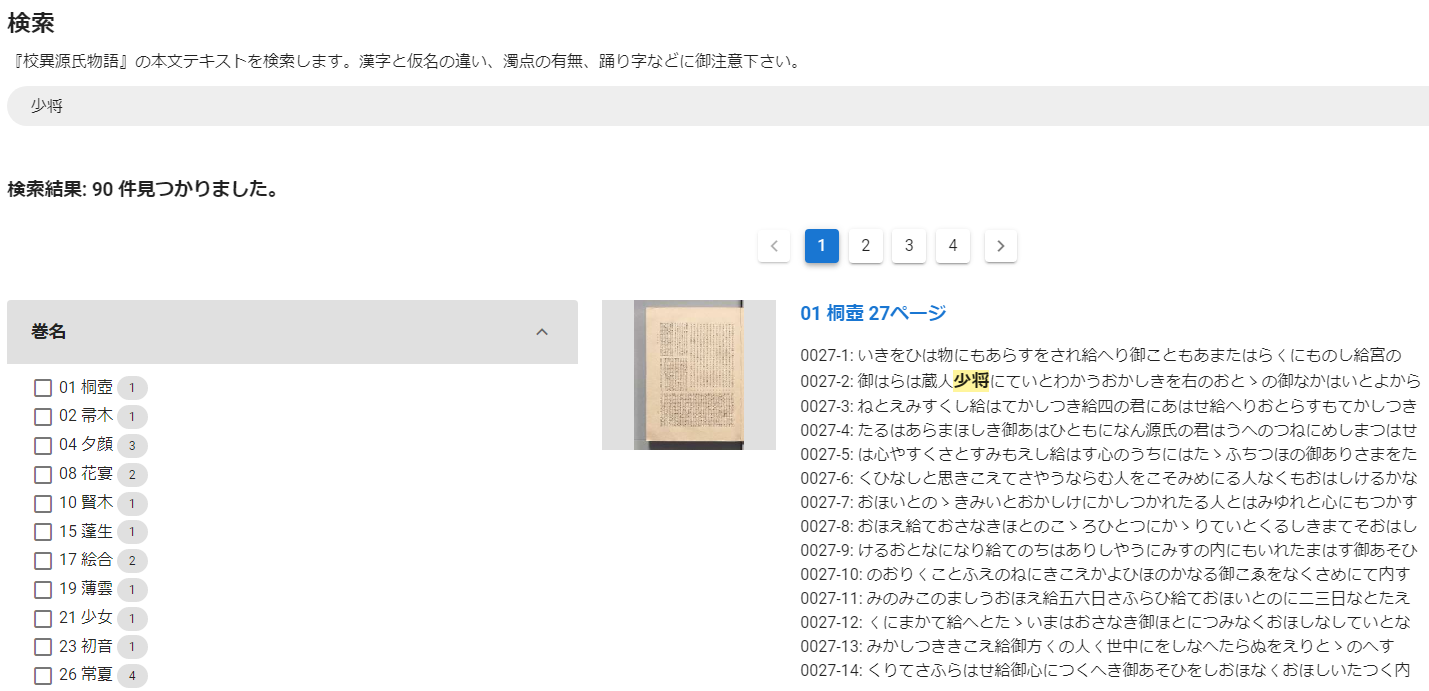
如图,我们以“少将”为检索词,检索结果按章节显示。

如图,点击《夕雾》章,网站即列出了与搜索结果匹配的草书体版本图像,来自于伝嵯峨本、平松家本、中院文库本等多版本。
评价
评价一个数字人文项目时,我们可以使用“FAIR”原则作为评判标准。“FAIR”代表了数据可用性的四个方面:Findable(可查询)、Accessible(可获取)、Interoperabe(可互操作)、Reusable(可重用)。
总体而言,该项目较好地符合了这一标准。网站所有数据资源,包括OCR文本、图片资料等,都可通过搜索功能,或是按章节、页码进行查询,并且都能免费保存下载。该站所用图片符合“国际图象互操作框架”(IIIF);而OCR文本则符合“文本编码标准”(TEI),文本能以XML或JSON格式打开,数据的可互操作性强。此外,每一种资源还附有使用许可协议,大部分为CC BY许可协议,用户可在署名的情况下自由使用资源。从网站呈现的角度来看,该网站结构合理,访问速度快,实际使用体验很舒适。
“数字源氏物语”项目很好地将文献学与数字人文相结合,为研究者提供了极大便利。我国古籍文献种类多,版本复杂,因此一个方便读者的“比较阅读平台”的建设十分重要。该项目的数字工具、网站呈现等方面,都是很好的案例,值得我们学习借鉴。